Is your Site Audit not running properly?
There are a number of reasons why pages could be blocked from the Site Audit crawler based on your website’s configuration and structure, including:
- Robots.txt blocking crawler
- Crawl scope excluding certain areas of the site
- Website is not directly online due to shared hosting
- Landing page size exceeding 2Mb
- Pages are behind a gateway / login
- Crawler blocked by noindex tag
- Domain could not be resolved by DNS—the domain entered in setup is offline
- Website content built on JavaScript—while Site Audit can render JS code, it can still be the reason for some of the issues
Troubleshooting Steps
Follow these troubleshooting steps to see if you can make any adjustments on your own before reaching out to our support team for help.
A Robots.txt file gives instructions to bots about how to crawl (or not crawl) the pages of a website. You can allow and forbid bots such as Googlebot or Semrushbot from crawling all of your site or specific areas of your site using commands such as Allow, Disallow, and Crawl Delay.
If your robots.txt is disallowing our bot from crawling your site, our Site Audit tool will not be able to check your site.
You can inspect your Robots.txt for any disallow commands that would prevent crawlers like ours from accessing your website.
To allow the Semrush Site Audit bot (SiteAuditBot) to crawl your site, add the following to your robots.txt file:
User-agent: SiteAuditBot
Disallow:
(leave a blank space after “Disallow:”)
Here’s an example of how a robots.txt file may look:

Note the various commands based on the user agent (crawler) that the file is addressing.
These files are public and in order to be found must be hosted on the top level of a site. To find a website’s robots.txt file, enter the root domain of a site followed by /robots.txt into your browser. For example, the robots.txt file on Semrush.com is found at https://semrush.com/robots.txt.
Some terms you may see on a robots.txt file include:
- User-Agent = the web crawler you are giving instructions to.
- Ex: SiteAuditBot, Googlebot
- Allow = a command (only for Googlebot) that tells the bot it can crawl a specific page or area of a site even if the parent page or folder is disallowed.
- Disallow = a command that tells the bot not to crawl a specific URL or subfolder of a site.
- Ex: Disallow: /admin/
- Crawl Delay = a command that tells bots how many seconds to wait before loading and crawling another page.
- Sitemap = indicating where the sitemap.xml file for a certain URL is.
- / = use the “/” symbol after a disallow command to tell the bot not to crawl the entirety of your site
- * = a wildcard symbol that represents any string of possible characters in a URL, used to indicate an area of a site or all user agents.
- Ex: Disallow: /blog/* would indicate all URLs in a site’s blog subfolder
- Ex: User-agent: * would indicate instructions for all bots
Read more about Robots.txt specifications from Google or on the Semrush blog.
If you see the following code on the main page of a website, it tells us that we’re not allowed to index/follow links on it, and our access is blocked.
<meta name="robots" content="noindex, nofollow" >
Or, a page containing at least one of the following: "noindex", "nofollow", "none", will lead to the error of crawling.
To allow our bot to crawl such a page, remove these “noindex” tags from your page’s code. For more information on the noindex tag, please refer to this Google Support article.
To whitelist the bot, contact your webmaster or hosting provider and ask them to whitelist SiteAuditBot.
The bot's IP addresses are: 85.208.98.128/25 (a subnet used by Site Audit only)
The bot is using standard 80 HTTP and 443 HTTPS ports to connect.
If you use any plugins (Wordpress, for example) or CDNs (content delivery networks) to manage your site, you will have to whitelist the bot IP within those as well.
For whitelisting on Wordpress, contact Wordpress support.
Common CDNs that block our crawler include:
- Cloudflare - read how to whitelist here
- Imperva - read how to whitelist here
- ModSecurity - read how to whitelist here
- Sucuri - read how to whitelist here
Please note: If you have shared hosting, it is possible that your hosting provider may not allow you to whitelist any bots or edit the Robots.txt file.
Hosting Providers
Below is a list of some of the most popular hosting providers on the web and how to whitelist a bot on each or reach their support team for assistance:
- Siteground - whitelisting instructions
- 1&1 IONOS - whitelisting instructions
- Bluehost* - whitelisting instructions
- Hostgator* - whitelisting instructions
- Hostinger - whitelisting instructions
- GoDaddy - whitelisting instructions
- GreenGeeks - whitelisting instructions
- Big Commerce - Must contact support
- Liquid Web - Must contact support
- iPage - Must contact support
- InMotion - Must contact support
- Glowhost - Must contact support
- Hosting - Must contact support
- DreamHost - Must contact support
* Please note: these instructions work for HostGator and Bluehost if you have a website on VPS or Dedicated Hosting.
If your landing page size or the total size of JavaScript/CSS files exceeds 2Mb, our crawlers will be unable to process it due to technical limitations of the tool.
To find out more about what could be causing the size increase and how to solve this issue, you can refer to this article from our blog.
To see how much of your current crawl budget has been used, go to Profile—Subscription Info and look for “Pages to crawl” under “SEO Toolkit.”
Depending on your subscription level, you are limited to a set number of pages that you can crawl in a month (monthly crawl budget). If you go over the number of pages allowed within your subscription, you’ll have to purchase additional limits or wait until the next month when your limits will refresh.
Additionally, If you encounter the error message "You've reached the limit for simultaneously run campaigns" during setup, it means you've hit the maximum number of site audits allowed to run at the same time for your subscription level.
Each subscription tier includes different limits:
- Free account: 1 site audit at a time
- Pro SEO Toolkit: Up to 2 simultaneous site audits
- Guru SEO Toolkit: Up to 2 simultaneous site audits
- Business SEO Toolkit: Up to 5 simultaneous site audits
If the domain could not be resolved by DNS, it likely means that the domain you entered during configuration is offline. Commonly, users have this issue when entering a root domain (example.com) without realizing that the root domain version of their site doesn’t exist and the WWW version of their site would need to be entered instead (www.example.com).
To prevent this issue, the website owner could add a redirect from the unsecured “example.com” to the secured “www.example.com” that exists on the server. This issue could also occur the other way around if someone’s root domain is secured, but their WWW version is not. In such a case, you would just have to redirect the WWW version to the root domain.
If your homepage has links to the rest of your site hidden in JavaScript elements, you need to enable JS-rendering, so that we are able to read them and crawl those pages. This feature is available with the Guru and Business tiers of the SEO Toolkit subscription.
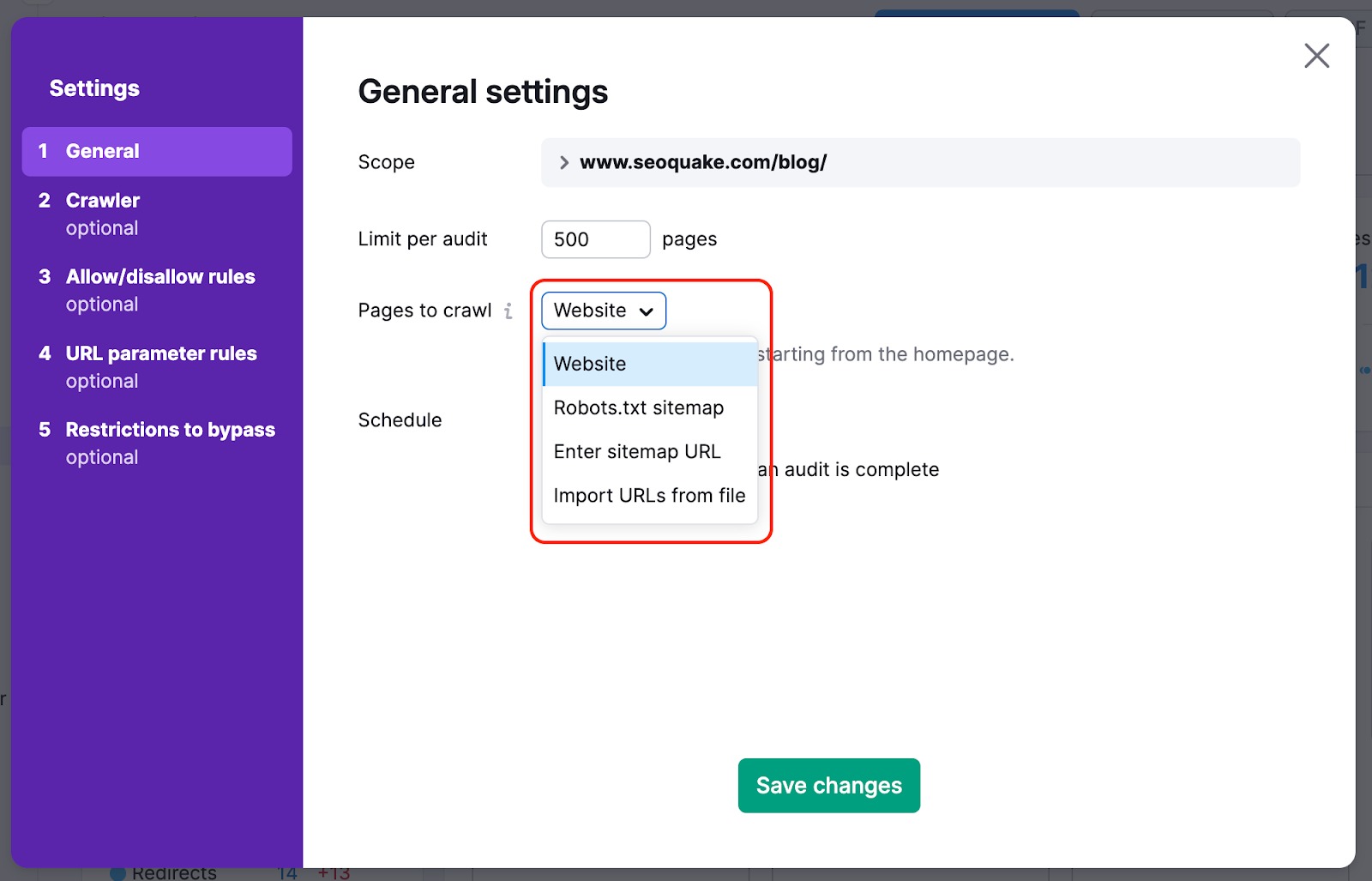
In order to not miss the most important pages on your website with our crawl, you can change your crawl source from website to sitemap—this way, crawlers won’t miss any pages that are difficult to find on the website naturally during the audit.
We can also crawl the HTML of a page with some JS elements and review the parameters of your JS and CSS files with our Performance checks.
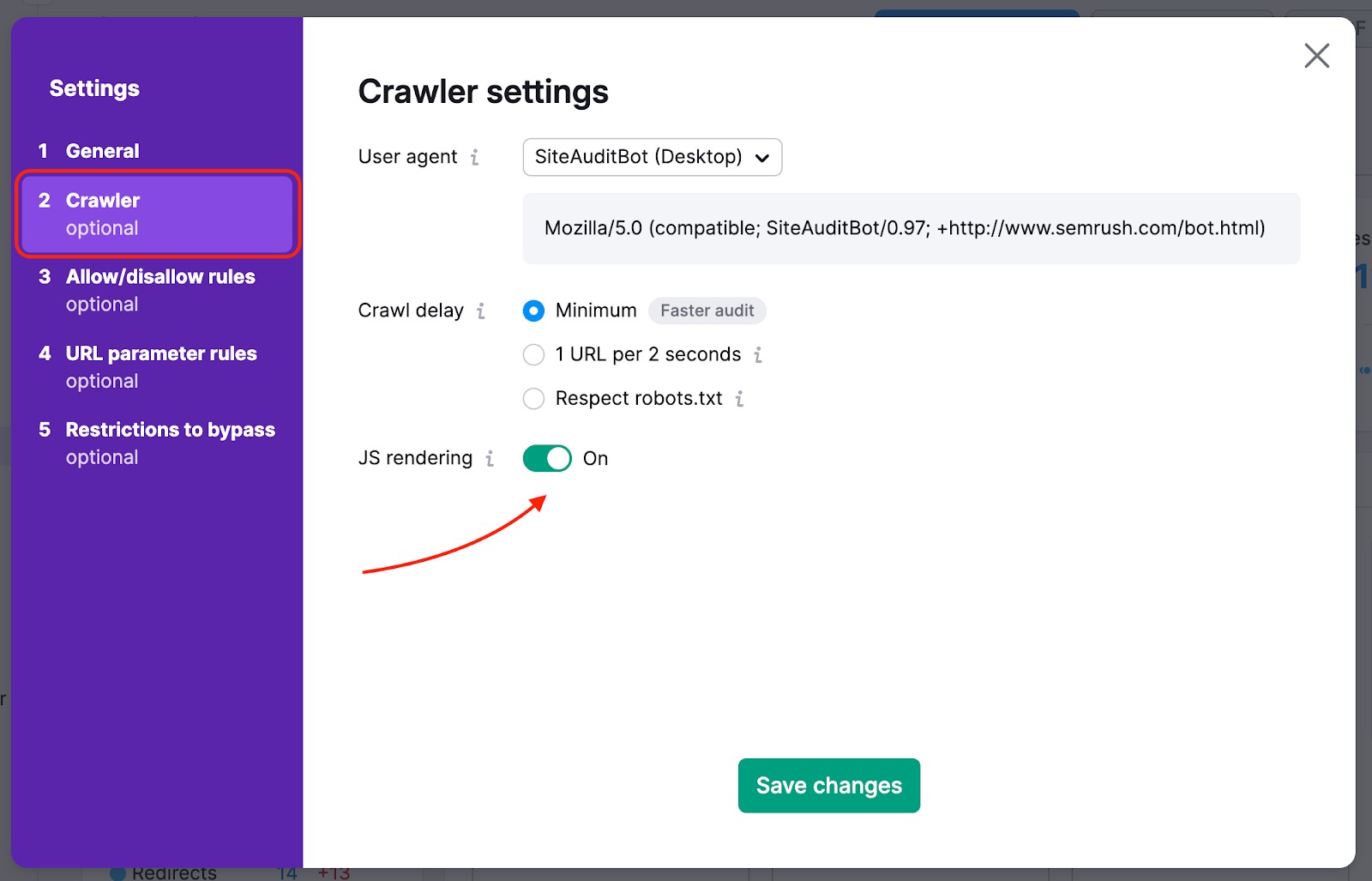
Your website may be blocking the SemrushBot in your robots.txt file. You can change the User Agent from SemrushBot to GoogleBot, and your website is likely to allow Google’s User Agent to crawl. To make this change, find the settings gear in your Project and select User Agent.
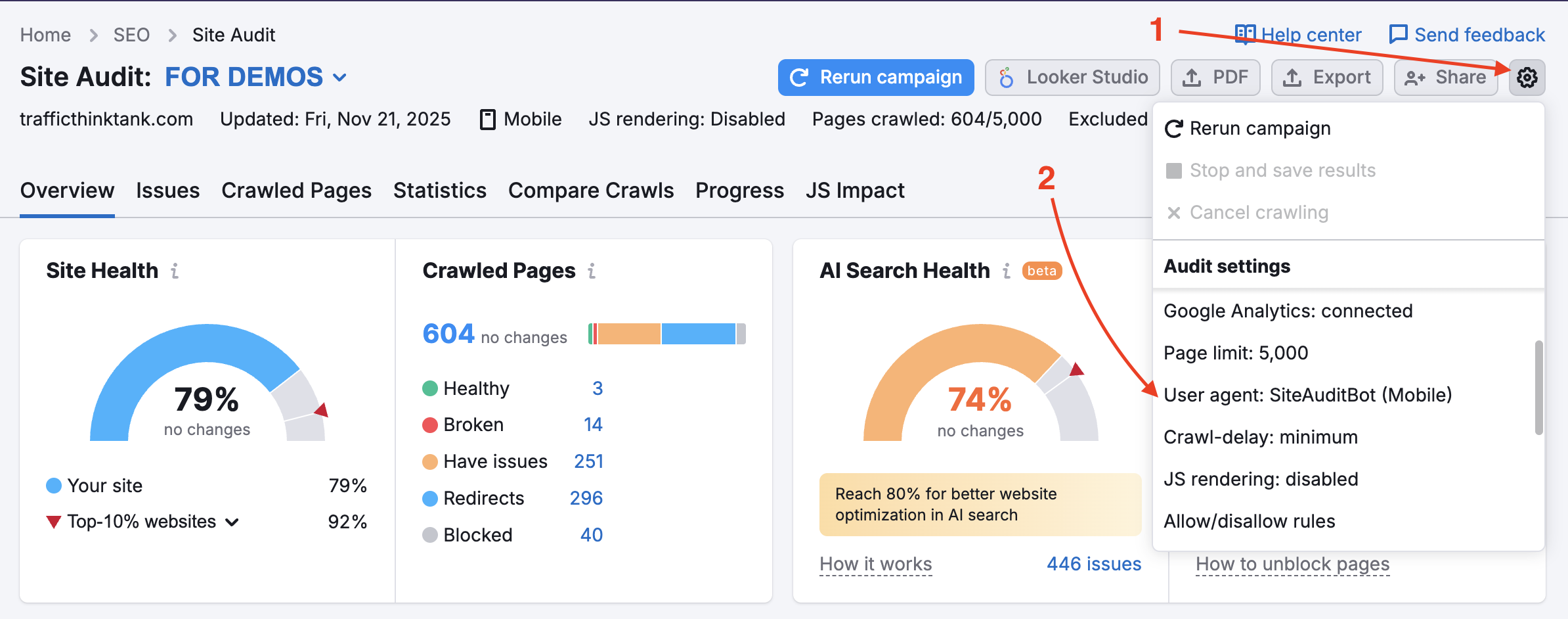
When this option is turned on, the crawler will bypass robots.txt disallow rules, so pages and internal resources that are normally blocked will still be crawled. Keep in mind that to use this, site ownership will have to be verified.
This is useful for sites that are currently under maintenance. It’s also helpful when the site owner does not want to modify the robots.txt file.
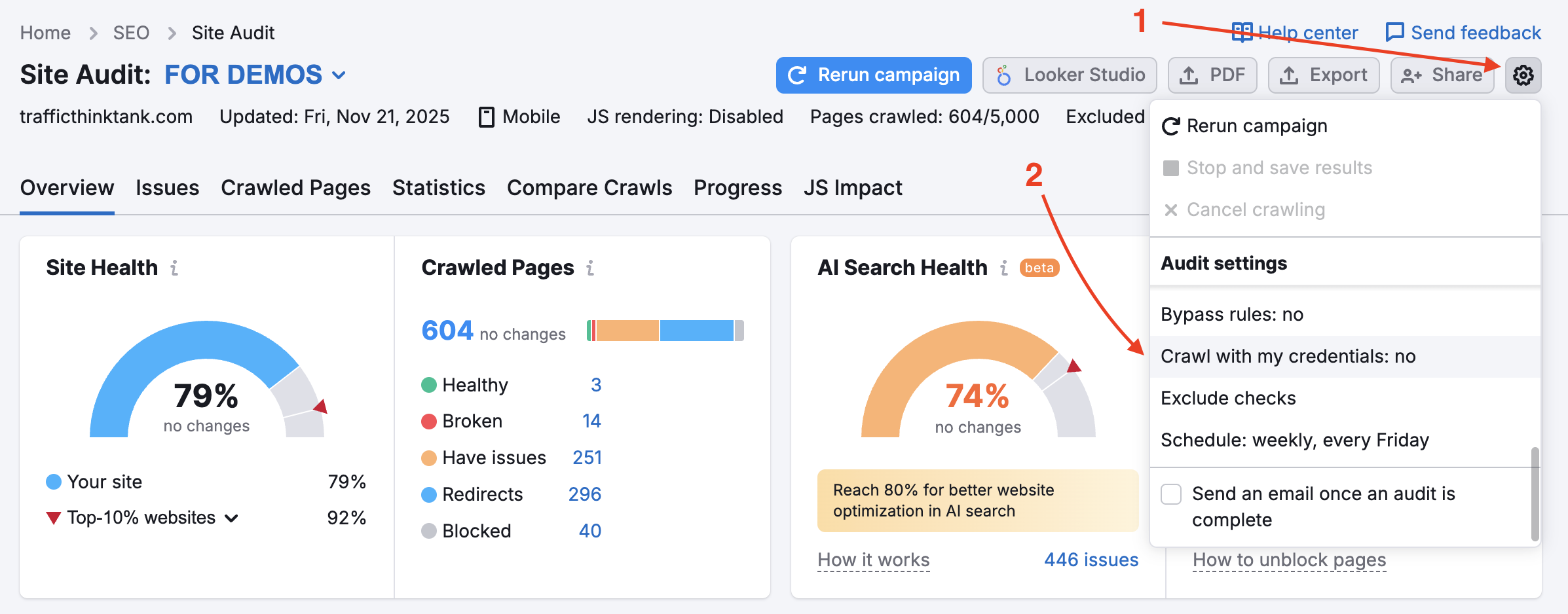
To audit private areas of your website that are password protected, enter your credentials in the “Crawling with your credentials” option under the settings gear.
This is highly recommended for sites still under development or are private and fully password protected.
“Your crawler settings have changed since your previous audit. This could affect your current audit results and the number of issues detected.”
This notification appears in Site Audit after you update any settings and re-run the audit. This is not an indicator of an issue but rather a note that if the crawl results changed unexpectedly, this is a likely reason for it.
Check out our blog post, Common SEO Issues & How to Fix Them.